
최초 작성일: 2020.10.19
최종 수정일: 2020.10.27
1. 시작
추천 시스템은 일상에서 굉장히 자주 사용되는 시스템으로 유투브, 네이버 등 다양한 사이트와 어플에서 사용된다.
사실상 인터넷에서 보는 모든것이 광고라고 보아도 무방할 정도이며 현대 사회에선 필수 요소이다.
추천 시스템은 콘텐츠 기반 필터링, 아이템기반 필터링 등 다양한 방법이 있다.
프로젝트를 진항하기 전 여러가지 추천 시스템들을 간단하게 살펴보았다.
2. 추천 시스템의 종류
1) 콘텐츠 기반 필터링 추천 시스템
사용자가 선호하는 아이템을 확인하고 아이템과 유사한 특성을 갖는 다른 아이템을 추천한다.
예)
사용자 A는 "살인자의 기억법", "봉제인형 살인사건", "셜록 홈즈"책을 온라인으로 구매한 이력이 있다.
이 때 3권의 책의 특성을 분석한다.
"살인자의 기억법"의 키워드: 추리, 스릴러, 영화원작, 장편소설
"봉제인형 살인사건"의 키워드: 스릴러, 추리, 미궁, 영미소설
"셜록홈즈"의 키워드: 소설, 명작, 추리, 스릴러
3권의 특성을 보면 추리, 스릴러 태그를 공통으로 갖고 있다. (실제론 태그 외에도 글쓴이, 출판일 등 다양한 요소를 고려한다)
이를 감안하여 유사소가 가장 높은 책 "그리고 아무도 없었다"를 추천한다.

콘텐츠기반 필터링 추천 시스템은 타겟 사용자 한 명을 분석하여 사용자의 취향을 알아내는 방식이다.
단, 이 방식은 사용자가 방금 가입한 사용자처럼 사용자에 관한 충분한 데이터가 쌓이지 않았을 경우 정확도가 떨어진다는 단점이 있다.
2) 최근접 이웃 협업 필터링
최근점 이웃 협업 필터링은 타겟 사용자와 유사도가 높은 다른 사용자의 평을 보고 추천 유무를 결정하는 시스템이다.
예)
사용자 A에게 "그리고 아무도 없었다"를 추천할지 말지 결정하기 위해 다른 사용자들이 책에 매긴 평점을 확인한다.

그리고 사용자간의 유사도를 확인한다. 사용자 B와 사용자 C중 사용자 A와 유사한 사용자는 사용자 B이다.
이는 사용자 A와 사용자 B의 선호도가 유사하다 할 수 있다. 그렇기에 사용자 B가 높은 평점을 매긴 "그리고 아무도 없었다"를 사용자 A에게 추천할 수 있다.
본 프로젝트는 아이템 기반 최근접 이웃 협업 필터링을 이용하기로 했다.
3. 데이터 수집 및 전처리
데이터는 kaggle 데이터셋을 이용했다.
www.kaggle.com/bahramjannesarr/goodreads-book-datasets-10m
Goodreads Book Datasets With User Rating 10M
Every 2 days , this dataset will be updated
www.kaggle.com
2020년 10월19일 기준 데이터는 27개의 파일로 이루어져 있으며 20개는 책에 대한 정보, 7개는 사용자 평점에 대한 정보를 갖고있다. 본 프로젝트에서는 user_rating_0_to_1000.csv파일 1개만을 사용했다.
해당 데이터는 1,000명의 사용자 평점 데이터를 갖고 있다.
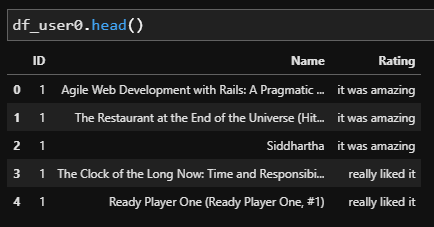
총 51,945개의 행과 ID, Name, Rating 3개의 컬럼으로 구성되어있으며 각 컬럼의 특징은 아래와 같다.
1) ID
사용자 ID이다. 0~999까지 총 1,000명의 사용자로 이루어져 있다.
한 명의 사용자는 여러 책에 평점을 남길 수 있기에 ID는 중복값이 많이 존재한다.

[그림 4]는 사용자가 얼마나 많은 책에 평점을 매겼는지 히스토그램으로 나타낸 것이다.
대략 0~10번, 300~400번, 850~950번대의 ID를 갖는 유저가 평을 많이 남겼다.
2) Name
도서명이다. 중복되는 이름의 도서가 존재할 수 있다.
3) Rating
사용자가 매긴 평점이다. 'This user doesn't have any rating', 'did not like it', 'it was ok', 'liked it', 'really liked it', 'it was amazing'로 구성되어있다. 문자열은 사용하기 불편하기에 각각 0, 1, 2, 3, 4, 5점으로 치환했다.


평점 빈도수인 [그림 6]을 보면 대부분의 책이 3~5점을 받았다.
수정된 데이터는 이후 사용하기 위해 csv파일로 저장했다.
4. 도서 추천 알고리즘 개발
1) 테이블 변환
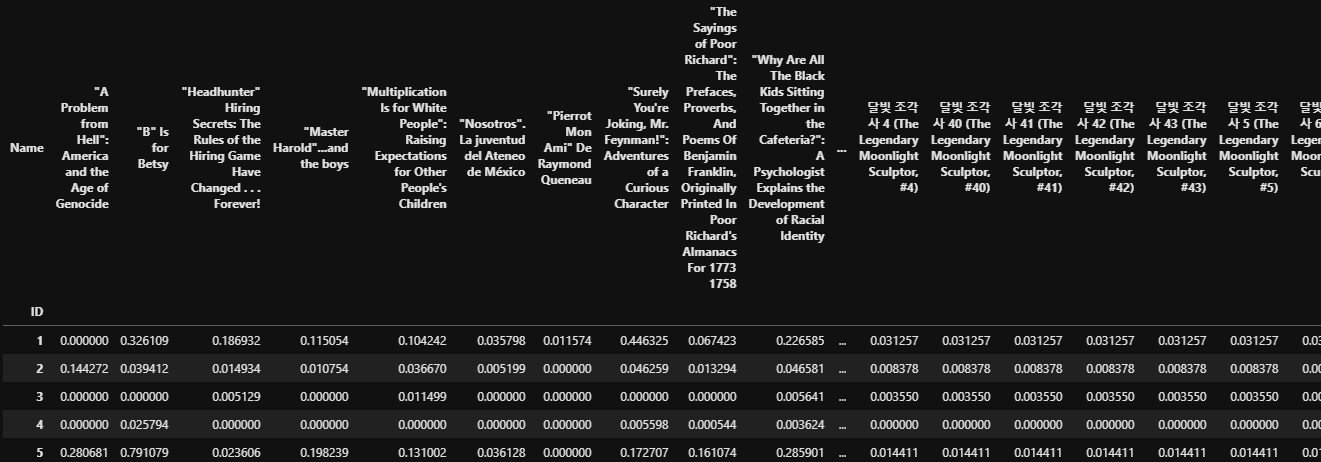
최근접 이웃 협업 필터링을 위해선 유저ID, 도서명, 평점으로 구성된 테이블을 [그림 2]와 같이 가로축은 유저, 세로축은 도서명, 데이터는 평점으로 구성된 테이블로 변환해야 한다.
pandas의 pivot_table()을 이용하여 테이블을 변환했다.
이 때 평점이 매겨지지 않은 데이터는 NaN으로 표기되므로 fillna(0)을 추가하여 NaN을 0으로 바꾸어 희소행렬을 만들었다.

2) 도서간 유사도 산출
아이템 기반 최근접 이웃 협업 필터링이기에 도서와 도서 사이의 유사도 측정이 필요하다.
사이킷런의 코사인 유사도를 이용하여 도서들 사이의 유사도를 비교했다.

3) 도서 추천
아이템기반 협업 필터링에선 아래의 식을 이용해 예측 평점을 구할 수 있다.
$$ \hat{R}_{u, i}= \frac{\sum n(S_{i, N}* R_{u, N})}{\sum N(\left | S_{i, N} \right |)} $$
$ \hat{R}_{u, i} $: 사용자$u$, 아이템$i$의 개인화된 예측 평점 값
$ S_{i, N} $: 아이템 $i$와 가장 유사도가 높은 Top-N개 아이템의 우사도 필터
$ R_{u, N} $: 사용자 $u$의 아이템 $i$와 가장 유사도가 높은 Top-N개 아이템에 대한 실제 평점 벡터
위의 식을 구현한 뒤 사용자-도서 테이블을 이용하여 사용자별 예측 평점을 구한다.
4) 성능평가
MSE를 사용해 실제 사용자가 매긴 평점과 3)에서 예측한 평점을 비교해 보았다.

약 7.48이 나왔다.
MSE를 줄이는 방향으로 모델을 조금 개선해보기로 했다.
5) 모델 개선
기존의 모델은 사용자가 평가한 도서와 다른 모든 도서 사이의 유사도 벡터를 비교했다.
다른 모든 도서를 비교했기에 효율성이 떨어지고 MSE가 높게 나온 것으로 추청했다.
그렇기에 도서간의 유사도를 산출하여 평가 도서와 유사한 도서들만 유사도 벡터를 적용했다.
6) 모델 평가
동일하게 MSE를 이용해 평가를 진행했다.

약 3.89로 기존의 7.48보다 개선된 것을 확인할 수 있었다.
7) 모델을 사용한 도서 추천
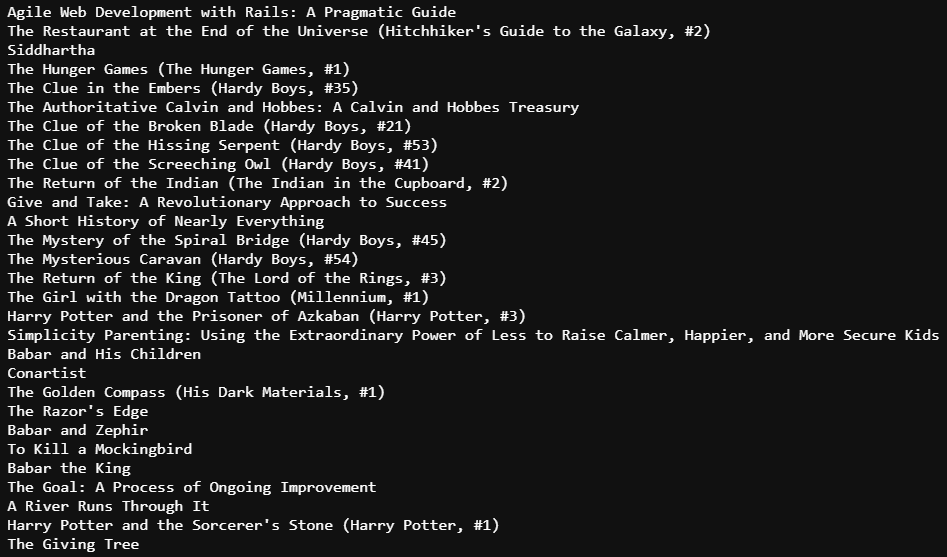
ID가 1인 사용자가 읽지 않은 도서중 추천도서 10권을 뽑아 보았다.

ID가 1인 사용자가 5점을 준 도서중 일부를 캡쳐했다.
5. 결론
사용자가 도서에 매긴 평점을 기반으로 추천 시스템을 만들었다.
추천된 도서를 실제로 사용자가 읽었는지, 평점을 매겼는지 알 수 없기에 MSE를 평가 지표로 삼았다.
입력 데이터의 일부를 제거하여 추천 도서에 제거된 데이터가 있는지 확인하는 방식으로 정확도를 계산할 수 있을 것 같다.
향후 행렬분해방식, 콘텐츠 기반 추천 서비스를 이용하는 프로젝트도 진행해보고 싶다.
6. 아쉬운 점, 더 해봐야 할 것들
1) 새로운 사용자, 새로운 도서가 추가된다면 4에서 수행한 작업을 다시 수행해야 한다. 사용자, 도서의 추가, 제거에 따른 유연한 대처 방법은 없을지 고민해보고 싶다.
2) 행렬분해, 콘텐츠기반 등 다른 추천 방식을 이용했을 때 차이를 확인해보고 싶다.
3) 신경망을 이용한 추천 프로젝트를 진행하고 차이점을 확인해보고 싶다.
7. 소스코드
github.com/mooooondh/BookRecommendation
mooooondh/BookRecommendation
Contribute to mooooondh/BookRecommendation development by creating an account on GitHub.
github.com
<출처 및 참고자료>
[1] 권철민. 파이썬 머신러닝 완벽 가이드 개정판. 위키북스
<이미지 출처>
[그림 1] 자체
[그림 2] 자체
[그림 3] 자체
[그림 4] 자체
[그림 5] 자체
[그림 6] 자체
[그림 7] 자체
[그림 8] 자체
[그림 9] 자체
[그림 10] 자체
[그림 11] 자체
[그림 12] 자체
[그림 13] 자체
'프로젝트' 카테고리의 다른 글
| [아쿠쿠아] v1.4.0 출시! (4) | 2024.02.25 |
|---|---|
| ASL 알파벳 번역기 만들기 2편 (0) | 2021.06.27 |
| ASL 알파벳 번역기 만들기 1편 (0) | 2021.06.02 |
| X-ray 사진을 이용한 폐렴 진단(CNN) (0) | 2020.10.06 |
| CNN으로 남성, 여성 구분하기 (0) | 2020.10.03 |