
최초 작성일 : 2021.06.27
최종 작성일 : 2021.06.27
본 내용은 "ASL알파벳 번역기 만들기 1편"에서 이어지는 내용입니다.
https://w-storage.tistory.com/39?category=1153960
ASL 알파벳 번역기 만들기 1편
최초 작성일 : 2021.06.02 최종 작성일 : 2021.06.02 1. 개요 및 목표 ASL 알파벳은 American Sign Language의 약자로 손을 이용해 알파벳을 표현한 지화(指話)이다. 청각 장애가 있거나 소리를 들을 수 없는 경
w-storage.tistory.com
1. 개요 및 목표
이번 프로젝트는 지난번 train된 모델을 활용하여 ASL알파벳 번역기 구현, 성능개선을 목표로 한다.

지난번 train을 통해 나온 모델의 성능은 약 95%의 accuracy를 가졌다.
이번엔 train된 모델을 영상을 이용해 실제로 사용했을 때의 성능을 확인해보자.
2. 파일 구조
하나의 파일에 모든 실행 코드를 넣는것은 코드 작성, 유지보수 등 여러 측면에서 비효율적이다. 그렇기에 각각 모듈로 나눠 한 모듈에선 하나의 동작만 진행하도록 프로젝트파일을 구성했다.
파일의 구조는 아래와 같다.

opencv를 이용해 웹캠의 영상을 받고, 이를 모델에 통과시켜나온 결과를 화면에 출력하게끔 구성했다.
그리고, 알파벳을 1초에 수십번 바꿀 일이 없고(가능할 것 같지도 않고) 속도저하를 어느정도 예방하기 위해 매 10번째 프레임(10, 20, 30....번째 프레임)만 모델에 통과시켰다.
그리고 입력할 영사이 필요한데 유튜브의 ASL설명 영상을 활용했다.
https://www.youtube.com/watch?v=u3HoC9_ir3s&ab_channel=TakeLessons
영상에서 A~Z까지 설명하는 부분만 추출하여 사용했다.
3. 결과확인
일단... 분류 성능이 좋아보이지도 않고 무엇보다 느리다!
실시간을 바라고 한건 아니고 어느정도 속도저하도 예상했으나 이건 너무 느리다!
속도 향상을 위해 모델을 mobilenetv3로 변경하고 다시 train을 진행했다.
4. mobilenetv3 재학습
pytorch에 포함되어있는 모델을 사용했다.
mobilenetv3는 small과 large가 있는데 large의 성능이 더 좋다.

small과 large 두 가지 모두 train을 진행했다.
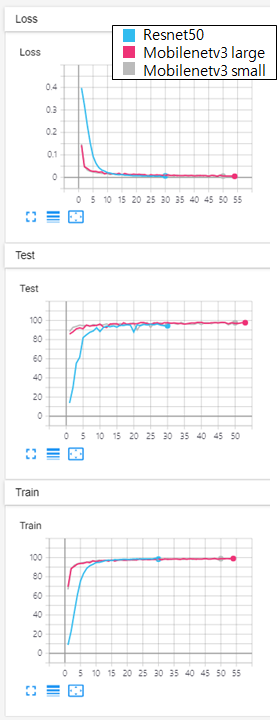
resnet만큼의 성능을 위해 epoch를 조금 더 늘려서 train을 진행했다.
결과를 살펴보면 samll과 large의 accuracy차이가 크게 보이지 않는다.
저장된 weight중 각각 성능이 제일 좋은것을 사용해 다시 영상을 입력해 보았다.
5. 다시 성능확인
모델의 마지막에 softmax를 추가하여 80%이상의 값을 갖는 경우에만 결과를 출력하게 했다.
mobilenetv3 large
mobilenetv3 small
mobilenetv3 small이 조금 더 속도가 빨랐다.
그럼 여기서 small이 지화를 얼마나 잘 분류했는지도 살펴보자.
출력이 있을 경우 해당 프레임을 저장하게 했고 저장된 프레임을 하나하나 확인해보았다.
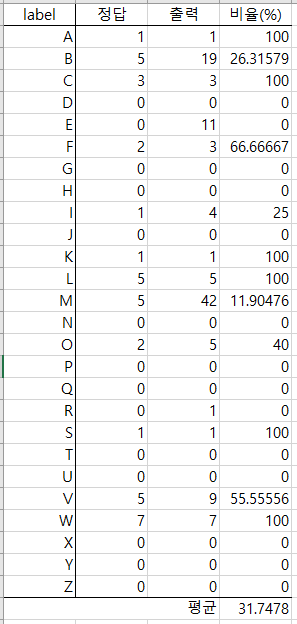
실제로 사용할 수 없을 만큼 처참한 성능이 나왔다...
왜 이런 결과가 나왔을까?
train에 사용한 결과를 확인해보자
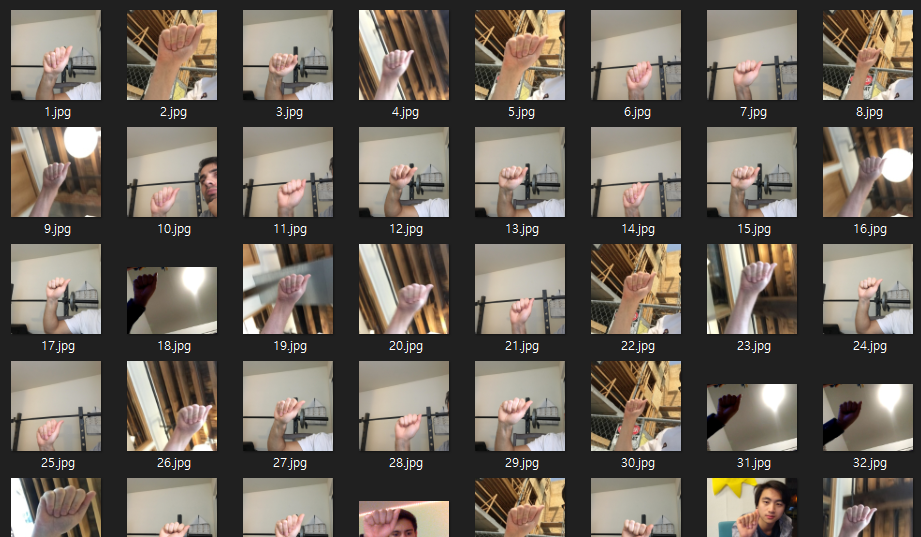
그렇다. train에 사용한 데이터는 손부분만 촬영된 사진이 대부분이었다. 사람이 함께 찍힌 이미지도 있으나 그 수가 부족했다.
그래서 이번엔 영상을 크롭하여 mobilenetv3 small에 통과시켜보았다.

음... 성능이 오르긴 했고 출력이 없는(출력이 0인)것을 제외하면 꽤 높은 accuracy가 나왔다.
precision과 recall은 엄청 떨어지겠지만....
결국, 실제로 사용하기 위해선 classification만을 사용하기 어렵다는 결론을 내릴 수밖에 없었다.
6. 결론
6월 중으로 마무리를 목표로 잡았기에.... 이 프로젝트는 실패다. 슬프지만 어쩔 수 없다.
어떤점이 부족했는지, 개선 방법은 어떤것이 있는지 고민해보았다.
1) 사진만을 이용해 classification을 train시켰기에 동영상과 환경이 다르다.(픽셀의 뭉게짐, noise 등...)
-> 동영상을 캡쳐하여 train시키면 성능이 조금 더 나아질지도?
2) 손부분만을 크롭된 이미지로 train시켰기에 실제 영상과는 다르다.
-> 솔직히 이게 큰 실패원인이라 생각한다. object detection을 이용해 손을 감지하고, 그 부분만 모델에 입력시켰다면 성능이 더 좋아졌을지도 모른다.
3) 실제 사용은 영상이기에 행동인식 모델 혹은, 이전 프레임과 비교하는 기능을 추가하면 더 나아질지도 모르겠다. 이를 이용하면 수화 번역도 가능하지 않을까?
4) 헷갈릴법한 동작들이 많다. 특히 A, M, N, T, S의 경우 주먹쥔 동작인데 엄지 손가락이 어디 있느냐에 따라 달라진다. 하지만 엄지 손가락의 위치를 인식시키긴 어려웠다.
향후 기회가 된다면 다시 도전해볼 것이다.
<이미지 출처>
[그림 1] 자체
[그림 2] 자체
[그림 3] https://pytorch.org/vision/stable/models.html
[그림 4] 자체
[그림 5] 자체
[그림 6] 자체
[그림 7] 자체
'프로젝트' 카테고리의 다른 글
| [React Native] component shaker 라이브러리를 만들었다 (0) | 2024.03.08 |
|---|---|
| [아쿠쿠아] v1.4.0 출시! (4) | 2024.02.25 |
| ASL 알파벳 번역기 만들기 1편 (0) | 2021.06.02 |
| 평점기반 도서 추천 (1) | 2020.10.27 |
| X-ray 사진을 이용한 폐렴 진단(CNN) (0) | 2020.10.06 |