
최초 작성일: 2021.01.25
최종 수정일: 2021.02.15
논문출처: arxiv.org/abs/1911.06644
You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization
Spatiotemporal action localization requires the incorporation of two sources of information into the designed architecture: (1) temporal information from the previous frames and (2) spatial information from the key frame. Current state-of-the-art approache
arxiv.org
한줄요약
2D-CNN과 3D-CNN을 한 모델에서 사용함으로써 기존의 단점을 해결하는 action localization모델 YOWO를 제안한다.
0. Abstract
기존의 action localization의 경우 다음과 같이 2개의 구조(two stage)를 이용해 구성한다.
1) 이전프레임으로 부터의 시각정 정보 획득
2) 키 프레임으로 부터의 공간적 정보 획득
YOWO는 2개의 분기점을 갖는 1개의 구조(single-stage)를 이용하여 기존의 문제점을 해결하였으며 real time action localization을 구현했다.
YOWO를 사용했을 때 16프레임 입력시 34fps의 처리가 가능하고 8프레임 입력시 62fps의 처리가 가능하다.
J-HMDB-21과 UCF101-24를 사용했을 때 각각 ~3%, ~12%의 성능 향상을 보였다.
1. introductoin
기존의 action localization은 video에서 action과 object detectiondms 2단계로 진행됐다.
1) action detection을 수행하고
2) classification, localization을 진행하여 개선
기존의 action localization은 video에서 action과 object detection 2단계로 진행됐다.
하지만 이 pipeline은 spatiotemporal action localization에서 3개의 큰 단점이 존재한다.
1) 프레임 간 bounding box로 구성된 action tubes 생성은 2D보다 복잡하고 시간이 오래걸림
2) video에서 사람의 동작만 집중. 사람과 물체, 배경의 상호작용은 무시함
3) 2개의 모델 구조를 갖기에 전체적으로 최적(global optimum)값을 찾을 수 없음 train비용이 높고, 시간이 오래걸리고, 메모리를 많이 사용함
YOWO(You Only Watch Once)를 사용해 action탐지와 localization을 한 개의 네트워크(single-stage network)에서 모두 수행함으로 인해 앞서 언급된 3가지 단점을 보완 할 수 있었다.
본 논문은 새로운 single-stage network YOWO(You Only Watch Once)를 제안한다.
YOWO는 video에서 action localization을 지원하며 단일 네트워크(single-stage network)에서 진행하기에 앞서 언급된 3가지 단점을 보완한다.
영상을 볼 때 사람의 시각 인지 시스템은 현재 프레임으로부터의 공간 정보와(2D key frame) 기억된 이전 프레임으로부터의 시간정보(3D clip)를 조합하여 상황을 판단한다.
YOWO는 이러한 사람의 시각 인지 시스템에서 영감을 받았다.

YOWO는 2개의 분기(branches)를 갖는 단일 네트워크(single-stage network)로 구성된다.
하나의 분기는 key frame을 추출하고 2D-CNN에 통과시킨다. 그동안 다른 분기는 이전 프레임들(clip)을 3D-CNN에 통과시킨다.
그리고 이 둘을 자연스럽게 합치기 위해 channel fusion 과 attention mechanism을 사용한 결과, 프레임 단위의 detection을 만들었다.
real time 성능을 위해 RGB타입 데이터를 사용해 YOWO를 동작시켰으나 optical flow, depth등의 데이터도 사용이 가능하다.
또한 2D-CNN 과 3D-CNN자리에 다른 CNN구조를 사용할 수도 있다.
YOWO는 입력으로 최대 16프레임을 받아 시공간 상의 action localization을 수행한다.
훈련된 3D-CNN을 사용하여 전체 비디오에 대해 겹치지 않는 8-프레임 클립에 대해 3D-CNN으로 기능을 추출하여long-term feature bank를 활용했고 마지막 perdormance에서 6.9%와 1.3%의 성능향상을 보였다.
2. Related Work
Action recognition with deep learning.
Spatiotemporal action localization.
Attention modules.
3. Methodology
YOWO의 구조는 다음과 같다
3D-CNN, 2D-CNN, CFAM, bounding box regression 4가지 큰 구조로 이루어져 있다.

3D-CNN
human action은 맥락이 중요하기에 3D-CNN에서 시공간적 특성을 추출하는 역할을 한다.
3D-CNN은 convolution을 통해 시간 차원과 공간 차원의 동작을 감지할 수 있다.
여기서 3D-CNN구조는 Kinetics dataset에서 높은 성능을 내는 3D-ResNext-101을 사용했다.
연속적인 프레임을 입력으로 할 때 shape은 $ [C × D × H × W] $이고 3D-ResNext-101의 출력은 $ [C' × D' × H' × W'] $이다.
$$ {C : color channel} \\
{D : 입력 프레임 갯수}\\
{W : 가로}\\
{H : 세로} $$
출력 feature map의 depth dimension은 2D-CNN의 출력과 일치시키기 위해 $ [C' × H' × W'] $로 압축(squeezed)시킨다.
$$ {C' : 출력 channel 갯수} \\
{D' : 1(압축될 때 사라짐)} \\
{H' : \frac{H}{32}} \\
{W' : \frac{W}{32}} $$
2D-CNN
spatial localization 문제를 해결하기 위해 키 프레임의 2D 기능도 병렬로 추출된다.
여기서 2D-CNN구조는 정확도와 효율성이 좋은 Darknet-19를 사용했다.
key-frame의 shape은 $ [C × H × W] $이고 Darknet-19의 출력 shape는 3D-CNN과 유사한 $ [C" × H' × W'] $이다.
$$ {C' : 출력 channel 갯수} \\
{H' : \frac{H}{32}} \\
{W' : \frac{W}{32}} $$
YOWO의 특징은 2D-CNN과 3D-CNN을 임의의 CNN구조로 바꿀 수 있기에 유연하다는 점이다.
Feature aggregation: Channel Fusion and Attention Mechanism (CFAM)
앞서 3D와 2D network의 출력 shape를 동일하게 했기 때문에 둘을 쉽게 결합할 수 있다. concatenation을 이용해 두 결과물을 쌓는다.
결과적으로, motion과 appearance information을 CFAM의 입력으로 인코딩 한다.

Bounding box regression
bounding box regression는 YOLO와 동일한 방식을 사용했다.
원하는 수의 출력 채널을 생성하기 위해 1×1 커널을 가진 마지막 층의 컨볼루션 레이어가 적용된다.
4. Experiments
YOWO를 검증하기 위해 UCF101-24와 J-HMDB-21 데이터셋을 사용했다.
3D network, 2D network or both?
3D-CNN, 2D-CNN중 하나만 사용해 spatiotemporal localization 문제를 풀 수는 있으나 둘을 함께 사용하면 성능이 증가한다.

3D-CNN, 2D-CNN과 CFAM까지 활용하여 측정하면 아래와 같은 결과가 나타난다.


backbone은 사람의 몸통쪽에 높은 가중치를 갖는것을 알 수 있다.
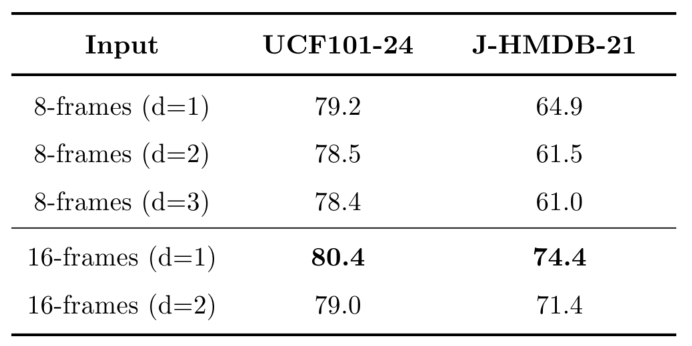
How many frames are suitable for temporal information?
3D-CNN branch에서 downsampling rate를 3으로 하고 8프레임과 16프레임 clip으로 YOWO를 실행한 결과이다.
Is it possible to save model complexity with more efficient networks?
저자는 많은 가중치를 갖는 모델이 복잡한 내용을 학습할 수 있다고 생각하여 3D-ResNext-101를 사용했다.
아래 table을 보면 모델이 가벼워질수록 성능이 떨어지는 것을 확인할 수 있다.

5. Conclusion
본 논문에서 저자는 비디오에서 시공간 action localization인 YOWO를 제시했다.
또한 UCF101-24 와 J-HMDB-21로 테스트를 수행했다.
본 방식은 실시간 동작이 가능하며 기존보다 좋은 성능을 내므로 모바일 기기에서 사용할 수도 있다.
후기
computer vision분야에서 사람의 행동을 감지하는 것은 오랜 기간동안 연구된 내용이다.
기본적으로 이를 위해선 1. 프레임에서 사람을 추출하고, 2. 이전 프레임과 비교하며 동작을 추측하는 방향으로 pipeline을 구성하였다.
YOWO는 앞선 1, 2의 동작을 동시에 수행함으로 pipeline의 문제점을 해결한다는 점에서 신선하게 생각하여 논문 리딩을 하게 되었다.
논문을 읽어본 적은 몇 차례 있었으나 이 처럼 처음부터 끝까지 정독하고 이렇게 기록으로 남기는 것은 처음이다.
그렇기에 같은 부분도 여러번 읽고, 내가 이해한 것이 맞는지 여러번 확인했으나 아직도 잘못 쓴 부분이 있어 보이기도 하고 단순히 번역, 요약만 한 글 같기도 하다.
하지만 논문의 구성을 어떻게 해야하는지, 읽는 사람에게 기술적 내용을 전달하려면 어떻게 해야하는지 배울 수 있었다.
비록 이번 논문리딩은 부족한 점 투성이지만 이를 반복하면 점차 개선해 나갈 수 있을 것이라 기대한다.
'딥러닝' 카테고리의 다른 글
| [CS231n] Lecture 2. Image Classification (0) | 2021.07.18 |
|---|---|
| 파이토치에서 텐서보드 사용하기 (0) | 2021.06.15 |
| [번외] CPU와 GPU의 학습 속도 (0) | 2020.10.13 |
| 순전파/역전파 (0) | 2020.09.24 |
| 활성화 함수 (0) | 2020.09.20 |