
본 포스팅은 CS231n의 2강 Image Classification을 정리한 내용입니다.

우리가 이미지의 색, 형태 등을 보고 물체가 무엇인지 구분한다. 하지만 컴퓨터에 실제로 입력되는것은 가로,세로, 채널 갯수만큼의 픽셀값이며 이는 작은 변화(고양이가 움직임, 일부가 가려짐, 빛의 변화 등)에도 전혀 다른 값으로 인식할 수 있다. 또한 한 이미지에 고양이가 여러마리 있거나, 다른 동물이 같이 있는 경우도 있을 것이다.
우리의 뇌는 이런 복잡한 상황에서도 분류를 잘 하지만 컴퓨터는 그렇지 못하다. 그렇기에 이를 인식하기 위한 여러 알고리즘이 고안되었다.
Nearest Neightbor classifier(NN)
매우 단순한 알고리즘으로, 공간을 나눠 각 레이블로 분류하는 알고리즘이다.
train 과정에서 모든 이미지를 저장하고, predict 과정에서 입력 이미지를 저장된 이미지와 비교한다.
여기서 두 이미지를 비교하는 방법으로 L1 distance를 사용한다.
L1 distance
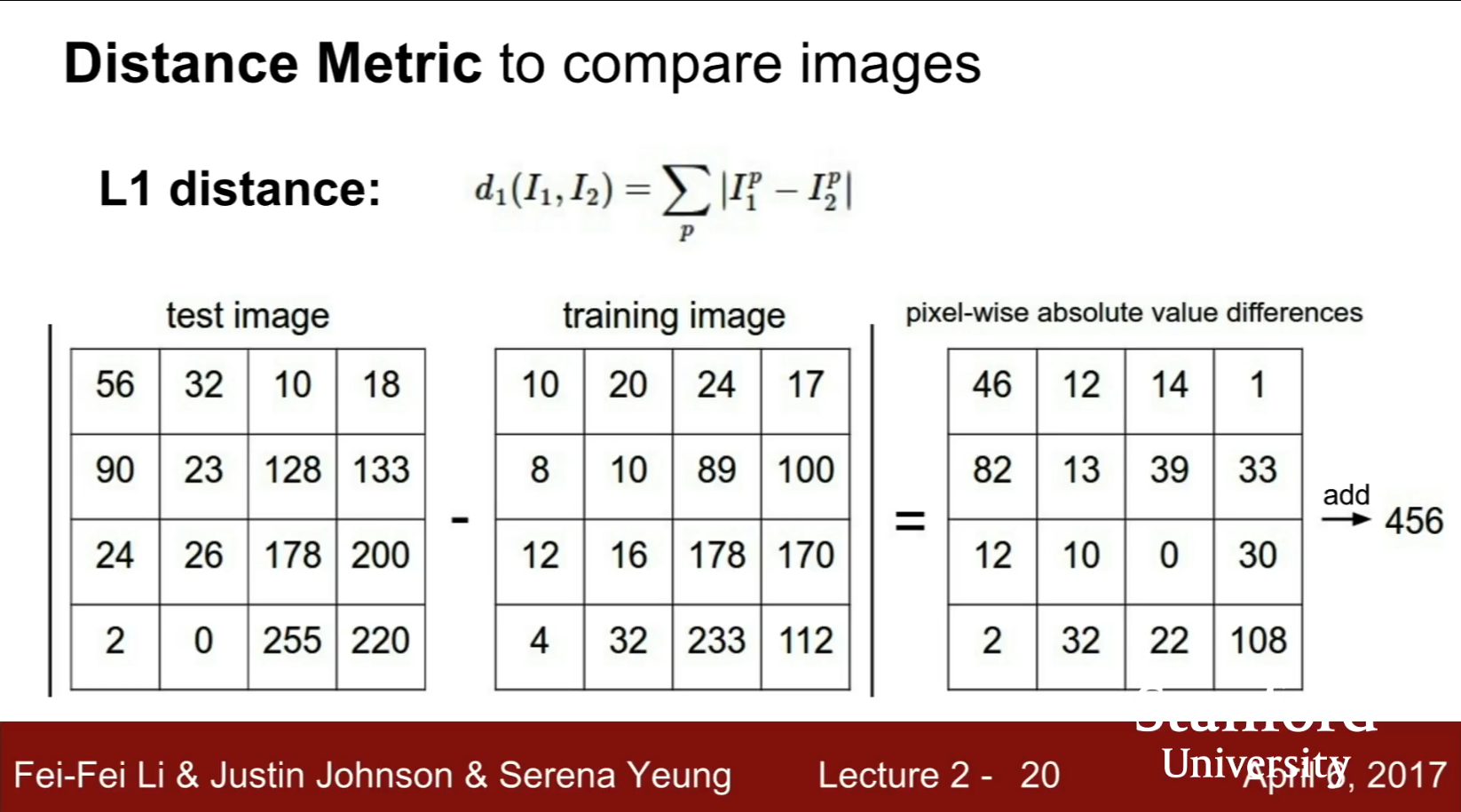
L1 distance 구현
import numpy as np
class NN:
def __init__(self):
pass
def train(self, x, y):
self.x_train= x
self.y_train= y
def predict(self, x):
num_test= x.shape[0]
y_pred= np.zeros(num_test, dtype= self.y_train.dtype)
for i in range(num_test):
distances= np.sum(np.abs(self.x_train - x[i, :]), axis= 1) # L1 distance
min_index= np.argmin(distances) # 최소값 index
y_pred[i]= self.t_train[min_index]
return y_pred
결과 시각화

동작시간
train time : O(1) ∵ 이미지를 저장만 하면 됨
predict time : O(N) ∵ 이미지들을 비교해야 함
→ 실제상황에선 train은 느려도 괜찮지만 predict는 빨랐으면 한다. 이 점에서 원하는 바의 정반대이다.
또한, NN은 공간을 나눠 레이블로 분류하기에 발생 가능한 문제가 있음
1) 녹색 영역 가운데 노랑색이 있음
2) 파랑-빨강, 파랑-녹색 영역이 서로 침범 (noise, spurious 등)
이러한 문제를 해결하기 위해 k-NN알고리즘이 탄생했다.
k-Nearest Neighbors(k-NN)
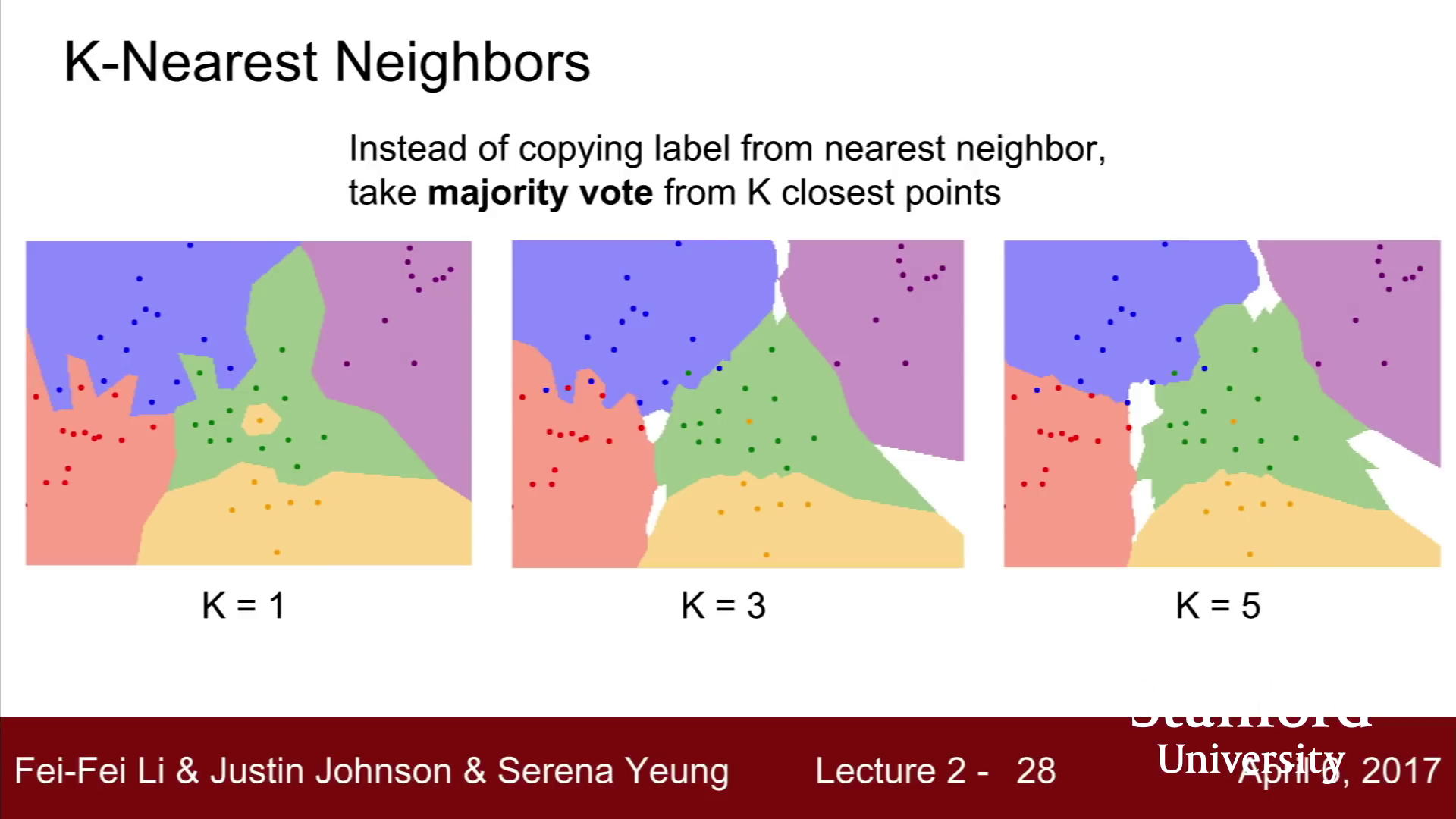
k-NN은 Distance metric을 이용해 가까운 k개의 이웃을 찾고, 이웃끼리 투표하여 결정하는 방식이며, 투표 방법은 여러 방법(거리에 따른 가중치)등 여러 방법이 존재한다. 이를 통해 NN에서 발생했던 문제들을 해결할 수 있다.
여기서 서로 다른 두 점을 비교하기 위해 L1 distance와 L2 distance를 사용한다.
1) L1 distance
$$ d_{1}(I_{1}, I_{2})= \sum_{p}^{}\left | I_{1}^{p} - I_{2}^{p} \right | $$
특징 벡터의 요소들이 각각 의미를 갖는 경우 사용(키, 몸무게 등)
좌표계에 의존적인 경우
2) L2 distance
$$ d_{2}(I_{1}, I_{2})= \sqrt{\sum_{p}^{}(I_{1}^{p} - I_{2}^{p})^2} $$
특징 벡터가 일반적 벡터이고, 요소들간의 실질적 의미를 잘 모르는 경우 사용
좌표계에 의존적이지 않은 경우
거리의 척도를 정할 수 있다면 어떤 문제에든 적용할 수 있다.
하이퍼파라미터 선택
k를 몇으로 할지, L1, L2중 어떤 것을 사용할지 등 개발자가 정해야 할 내용들을 하이퍼파라미터라 한다.

데이터를 train, validation, test로 나누고 train데이터로 학습, validation의 데이터로 검증한다. test데이터는 프로젝트의 제일 마지막에 validation에서 가장 좋았던 분류기로 "오직 한번만"사용한다. 이 값이 최종 성능이 된다.
(k-fold는 데이터가 매우 적은 경우 사용되기에 딥러닝에서 잘 사용되지 않아 생략)
여기까지 k-NN에 대해 알아보았다. 하지만 사실, 이미지를 다루는 문제에서 k-NN은 좋은 방법이 아니다.
1) 느리고, 별로 좋지 않은 성능을 보인다.
2) L1, L2 distance가 이미지간의 거리(지각적 유사도)를 측정하기에 적절치 않다. 동일한 이미지에 약간의 변화가 생기면 거리가 달라진다.
3) 차원의 저주에 빠지기 쉽다. 가장 가까운 이웃이 매우 멀리 떨어져있을 수 있다.

또한 k-NN은 "차원의 저주"에 빠지기 쉬운데, 차원의 저주는 차원이 커질수록 학습 데이터가 기하급수적으로 증가하는 현상을 말한다.

Linear classification
가장 간단하지만 매우 중요한 CNN의 기반 알고리즘
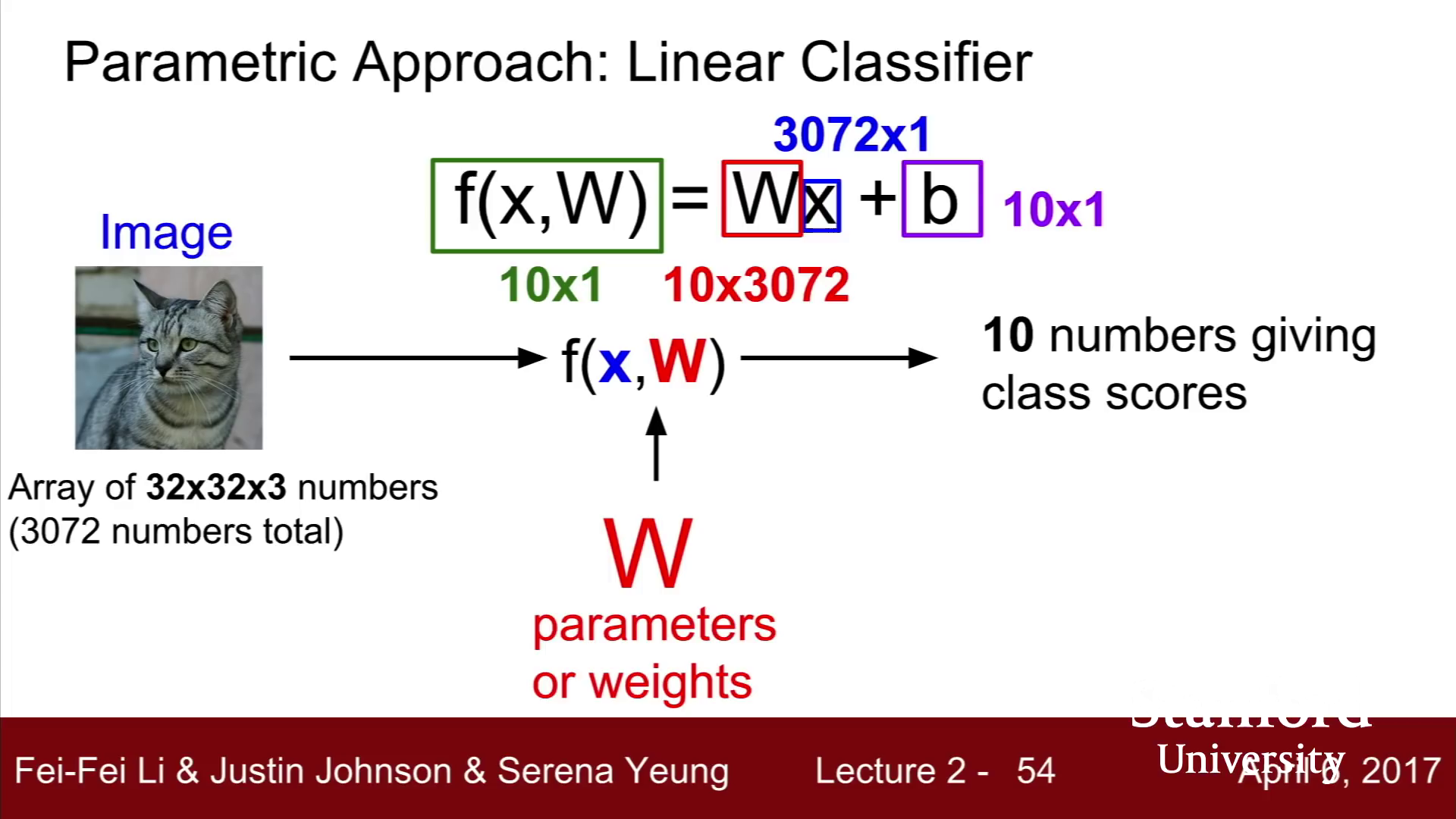
입력 x에 대해 적절한 w(weight)를 찾는 과정으로, NN에서처럼 모든 이미지를 저장할 필요 없이 w만 알고 있으면 되기에 효율적이다.
b는 클래스에 우선권을 주는 역할로, 데이터 불균형을 해결할 수 있다.

이미지를 고차원상의 한 점으로 볼 때 Linear classification는 각 이미지를 구분짓는 경계선을 긋는다.
하지만 Linear classification은 완벽하지 않으며 XOR등 Linear classification만으로 해결할 수 없는 문제도 있다.
'딥러닝' 카테고리의 다른 글
| Lecture 3. Loss Functions and Optimization (0) | 2021.07.25 |
|---|---|
| 파이토치에서 텐서보드 사용하기 (0) | 2021.06.15 |
| [논문리딩] YOWO(You Only Watch Once) (0) | 2021.01.25 |
| [번외] CPU와 GPU의 학습 속도 (0) | 2020.10.13 |
| 순전파/역전파 (0) | 2020.09.24 |